SGUIE-Net: Semantic Attention Guided Underwater Image Enhancement with Multi-Scale Perception
Qi Qi1, Kunqian Li2*, Haiyong Zheng1, Xiang Gao2, Guojia Hou3, Kun Sun4
1College of Information Science and Engineering, Ocean University of China
2College of Engineering, Ocean University of China
3College of Computer Science and Technology, Qingdao University
4School of Computer Science, China University of Geosciences
Abstract
Due to the wavelength-dependent light attenuation, refraction and scattering, underwater images usually suffer from color distortion and blurred details.However, due to the limited number of paired underwater images with undistorted images as reference, training deep enhancement models for diverse degradation types is quite difficult. To boost the performance of data-driven approaches, it is essential to establish more effective learning mechanisms that mine richer supervised information from limited training sample resources. In this paper, we propose a novel underwater image enhancement network, called SGUIE-Net, in which we introduce semantic information as high-level guidance via region-wise enhancement feature learning. Accordingly, we propose semantic region-wise enhancement module to better learn local enhancement features for semantic regions with multi-scale perception. After using them as complementary features and feeding them to the main branch, which extracts the global enhancement features on the original image scale, the fused features bring semantically consistent and visually superior enhancements. Extensive experiments on the publicly available datasets and our proposed dataset demonstrate the impressive performance of SGUIE-Net.
[Paper] [Code] [Supplementary] [DataSet]
Highlights
-
We propose a semantic attention guided underwater image enhancement network called SGUIE-Net. It learns enhancement features incorporating semantic clues to help recover those degradations that are uncommon in the training sample distribution but semantically relevant with the well-learned types.
-
We design SGUIE-Net as a deep enhancement network with multi-scale perception, whose main branch for global-wise learning and semantic branch for region-wise learning are fused to complement each other. The main branch is used to provide end-to-end enhancement while preserving image texture details in original scale, and the semantic branch is used to complement the semantic attention guided features with multi-scale perception.
-
We establish a new benchmark, namely SUIM-E, by extending the Segmentation of Underwater IMagery (SUIM) dataset with corresponding enhancement reference images. Then, comprehensive experiments, evaluations and analyses conducted on multiple commonly used datasets verify the good performance of the proposed SGUIE-Net.
Overall Architecture
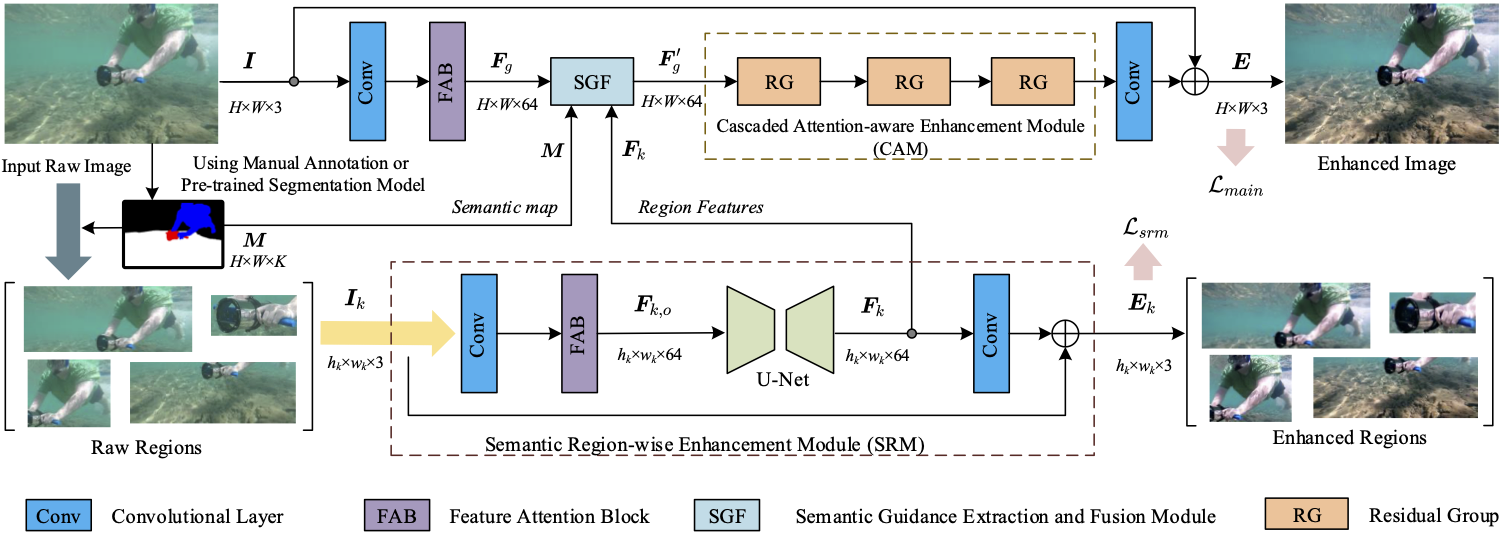
Fig 1. The architecture of SGUIE-Net. Our SGUIE-Net contains two enhancement branches for multi-scale perception, the main (top) branch works on the original input scale through the cascaded attention-aware enhancement module (CAM) which contains three residual groups (RGs), and additionally embeds a semantic guided feature extraction and fusion module (SGF) to receive enhanced multi-scale features. The bottom branch learns multi-scale enhancement features with semantic attention using an encoder-decoder structure. It builds semantic enhancement guidance through the semantic region-wise enhancement module (SRM) and then feeds them back to the main branch. The details of the FAB, RG and SGF modules are shown in Figure 2.
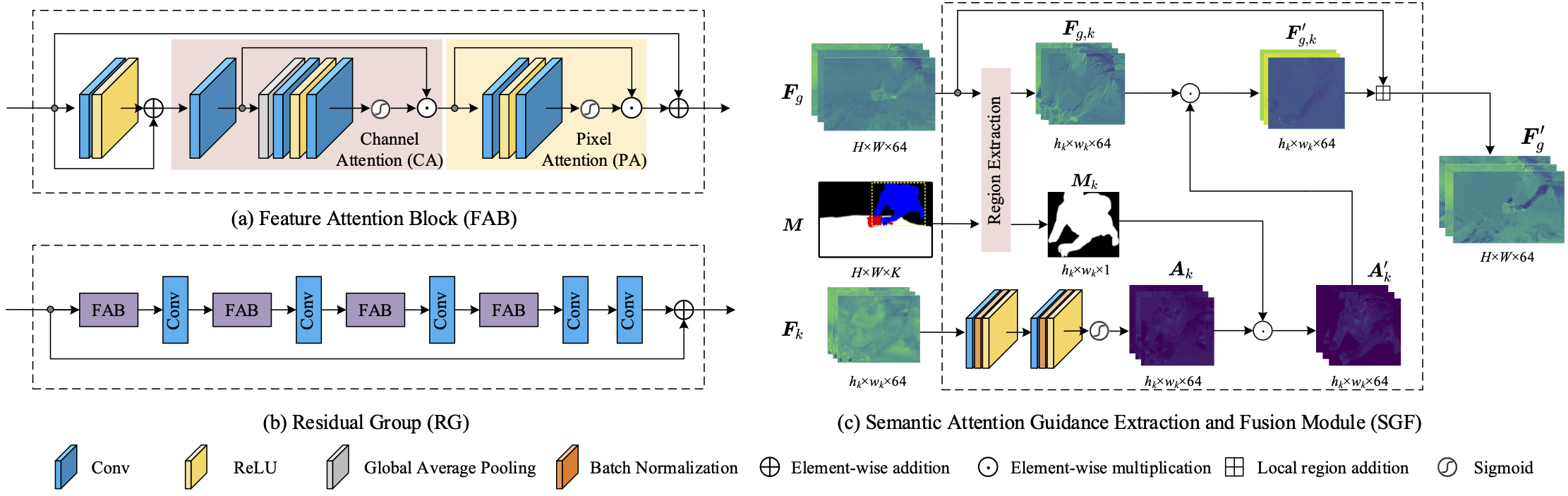
Fig 2. The architectures of the basic blocks of our SGUIE-Net. (a) Feature attention block (FAB) consists of cascaded channel attention (CA) and pixel attention (PA) module. (b) illustrates the RG module formed by multiple FABs with shorted connections. (c) The SFG module takes the global intermediate residual feature Fg, semantic mask M and the region-wise residual enhancement feature Fk as the inputs. Then, the SFG module extracts the local parts of Fg according to the semantic guidance of M for the later fusion with Fk.
Results

Fig. 3. Visual comparisons on underwater images from SUIM-E test set. The perceptual score is marked on the upper right corner of each enhancement.

Fig 4. Visual comparisons on underwater images from UIEB Challenging set (the top two rows), RUIE (the middle two rows) and EUVP (the bottom two rows) datasets. The perceptual score is marked on the upper right corner of each enhancement.

Fig 5. Visual comparisons on challenging underwater images from SQUID. The perceptual score is marked on the upper right corner of each enhancement.
Citation
@article{qi2022sguienet,
title={SGUIE-Net: Semantic Attention Guided Underwater Image Enhancement with Multi-Scale Perception},
author={Qi Qi and Kunqian Li and Haiyong Zheng and Xiang Gao and Guojia Hou and Kun Sun},
journal={IEEE Transactions on Image Processing},
volume={31},
pages={6816--6830},
year={2022},
publisher={IEEE}
}