TCTL-Net: Template-free Color Transfer Learning for Self-Attention Driven Underwater Image Enhancement
Kunqian Li1, Hongtao Fan1, Qi Qi2*, Chi Yan1, Kun Sun3, Q. M. Jonathan Wu4
1College of Engineering, Ocean University of China
2School of Information and Control Engineering, Qingdao University of Technology
3School of Computer Science, China University of Geosciences
4Department of Electrical and Computer Engineering, University of Windsor
Abstract
Vision is an important source of information for underwater observations, but underwater images commonly suffer severe visual degradation due to the complexity of the underwater imaging environment and wavelength-dependent absorption effects. There is an urgent need for underwater image enhancement techniques to improve the visual quality of underwater images. Due to the scarcity of high-quality paired training samples, underwater image enhancement based on deep learning has never achieved success similar to other vision tasks. Instead of learning complicated distortion-to-clear mappings with deep networks, we design a template-free color transfer learning framework for predicting transfer parameters, which are more easily captured and described. In addition, we add attention-driven modules to learn differentiated transfer parameters for more flexible and robust enhancement. We verify the effectiveness of our method on multiple publicly available datasets and show its efficiency in enhancing high-resolution images.


Highlights
-
We re-formulate color transfer and incorporate it into a deep-learning framework for underwater image enhancement, which does not require any candidate templates in the test stage (i.e., the target or reference images in image color transfer).
-
We propose to use self-attention and introduce lightness (L*) channel fusion for joint attention guidance to address color degradation perception. By further dividing the transfer parameter prediction into basic ones for the whole channel and biased parameter matrices for local regions, our approach enables differentiated enhancements for regions with diverse and uneven degradation.
-
Unlike traditional deep UIE models, which have to sacrifice output resolution to overcome computational power and space barriers, TCTL-Net has better compatibility with high-resolution images. By using basic transfer parameters as robust global guidance, TCTL-Net only needs to predict low-resolution biased transfer parameter matrices in order to generate region-wise differentiated enhancement without sacrificing output resolution.
Overall Architecture
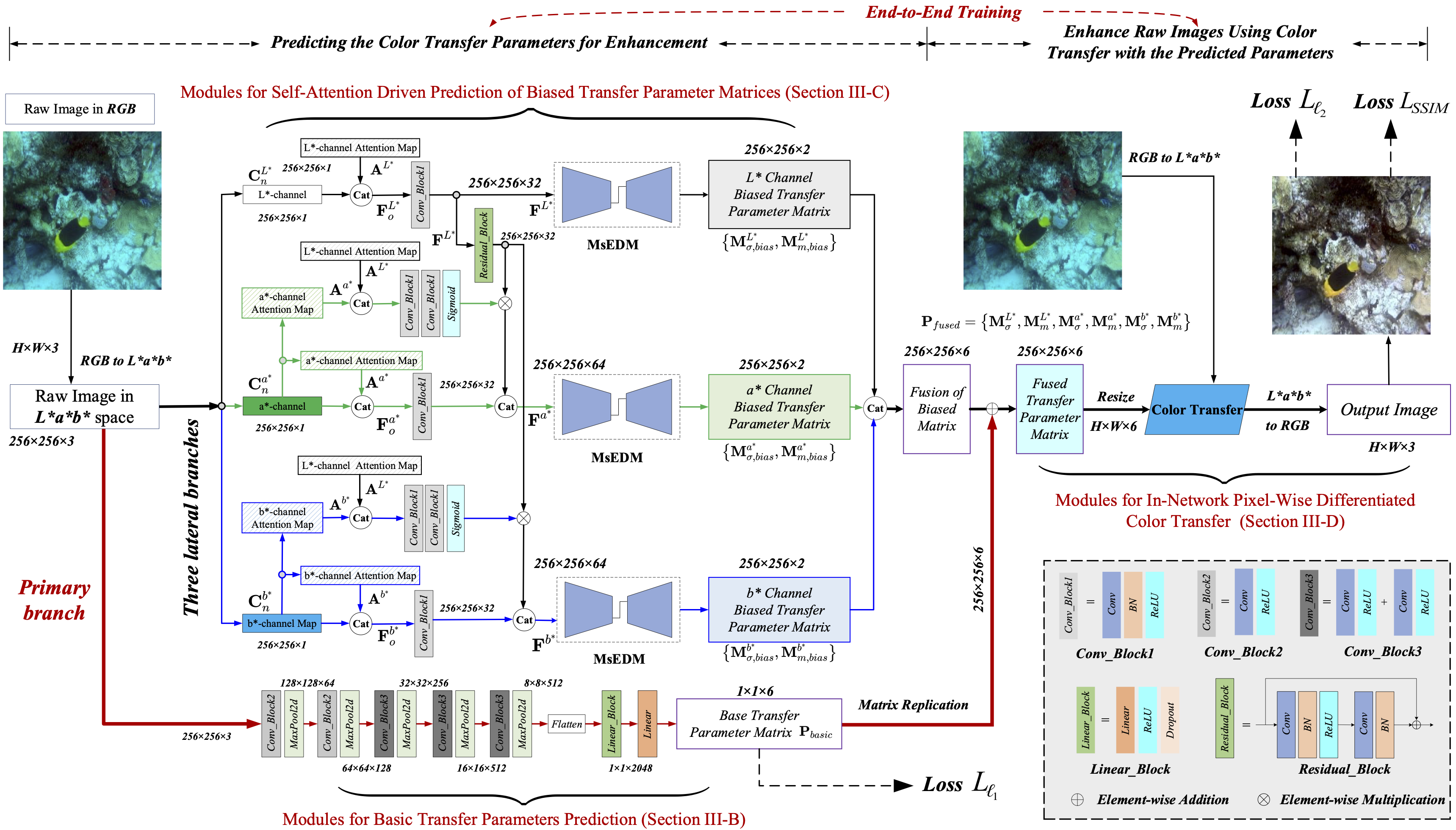
Fig 1. The overall architecture of TCTL-Net. TCTL-Net is designed as an end-to-end training framework that unifies the prediction of color transfer parameters and in-network color transfer-based enhancement into a single network. The parameter prediction modules consist of one primary branch for predicting the basic transfer parameter matrix and three lateral branches for predicting biased transfer parameter matrices of channels L*, a*, and b* respectively. The in-network color transfer module uses the predicted results to provide pixel-wise differentiated enhancement.
Results

Fig. 2. The visual comparison of enhancements on the images of the SQUID dataset. From left to right, (a) the raw images of SQUID from four dive sites, their enhancements with (b) Water-Net, (c) Ucolor, (d) UICoE-Net, (e) LCL-Net and (f) the proposed TCTL-Net are presented, respectively.

Fig. 3. The 3D models reconstructed from raw underwater images and enhanced underwater images using TCTL-Net. (a) is an example of the raw image from the Sea-thru dataset; (b) and (c) are the local perspectives of 3D models reconstructed using the raw underwater images like (a); (d) is the enhancement of (a) generated by the proposed TCTL-Net; (e) and (f) are the local perspectives of 3D models reconstructed using the enhanced underwater images of TCTL-Net. The size of the images used for 3D reconstruction is 1962 × 1310.